
 العربية
العربية Español
Español 中文
中文 Deutsch
Deutsch Français
Français Português
Português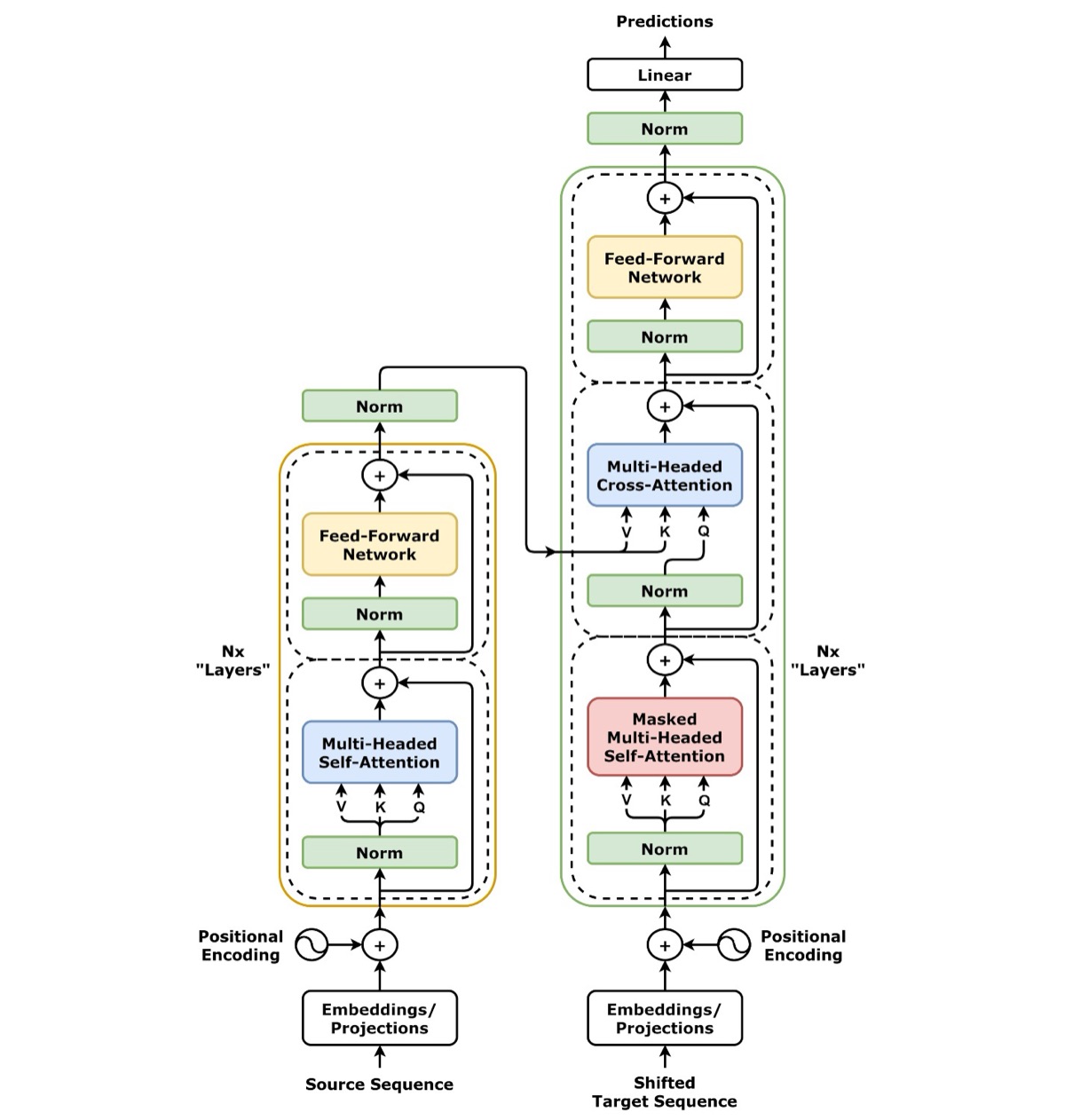
In June 2017, eight researchers at Google published a paper with a slightly cheeky title — Attention Is All You Need — and quietly rewired the future of artificial intelligence. The paper introduced a new kind of neural network called the Transformer. If you have used ChatGPT, Claude, Gemini, or almost any modern AI, you have used a descendant of the architecture described in those pages. The T in GPT and BERT literally stands for Transformer.
This is a tribute to what the paper proposed, why it broke the field wide open, and how one elegant idea — letting a model pay attention to everything at once — became the engine of the AI era.
- Title: Attention Is All You Need
- Authors: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin (all at Google; listed as equal contributors, order randomized)
- Posted: arXiv, June 12, 2017 (arXiv:1706.03762); presented at NeurIPS in December 2017
- What it introduced: the Transformer — a network built entirely on attention, with no recurrence and no convolution
- Why it matters: it is the foundation of the large language models — GPT, BERT, Claude, Gemini — and of image, audio, and protein models too
- Impact: cited more than 250,000 times by 2026, among the ten most-cited papers of the 21st century
1. The bottleneck before the Transformer
To appreciate the leap, picture how the best language models worked in 2016. They read a sentence the way you might read it aloud: one word at a time, strictly in order. These were recurrent neural networks (RNNs) and their more capable cousins, LSTMs. Each word was processed, a little summary of everything-so-far was updated, and only then could the next word be handled.
That design had two stubborn problems. First, it was sequential, so it could not take full advantage of the parallel horsepower of modern GPUs — you cannot start word 50 until you have finished word 49. Second, it had a memory problem: by the time the model reached the end of a long paragraph, the influence of the opening words had faded, making long-range connections hard to learn.
2. The big idea: attention
The Transformer’s answer was to throw out the sequence entirely and lean on a mechanism called self-attention. Instead of passing a summary hand-to-hand down a chain, self-attention lets every word look directly at every other word at the same time and decide, for each one, how much it matters.
Consider the sentence “the animal didn’t cross the street because it was too tired.” To know what “it” refers to, a model must connect “it” back to “animal.” Attention does exactly that: it computes, for the word “it,” a set of weights over all the other words, and learns to put most of that weight on “animal.” The paper’s formulation of this — scaled dot-product attention — is compact enough to write in a single line:
Every word emits a query (what am I looking for?), a key (what do I offer?), and a value (what I will pass on if selected). Matching queries against keys produces the attention weights; those weights then mix the values. Because this is all matrix multiplication, it runs massively in parallel — the exact thing GPUs are built for.
3. The architecture, in one picture
The authors wrapped self-attention into a clean, repeatable design (shown in the diagram above): an encoder that reads the input and a decoder that produces the output, each a stack of identical layers. Three ingredients made it work:
- Multi-head attention. Rather than computing attention once, the model runs several attention operations in parallel — different “heads” that can focus on different kinds of relationships (grammar, meaning, reference) at the same time.
- Positional encoding. Since the model no longer reads in order, it needs another way to know word order. The authors added smooth sine-and-cosine signals to each word’s representation, quietly stamping in where each token sits.
- Residual connections and normalization. These keep the signal stable as it flows through deep stacks of layers, so the network can be made large without falling apart.
Strip it down and the recipe is almost austere: attention, a small feed-forward network, and normalization, repeated. No recurrence. No convolution. Hence the title.
4. The results that turned heads
Elegance would not have mattered without numbers, and the numbers were emphatic. On the standard WMT 2014 machine-translation benchmarks, the Transformer set a new state of the art — 28.4 BLEU on English-to-German and 41.8 BLEU on English-to-French — while training far faster and cheaper than the models it beat.
The big Transformer reached its record score after just 3.5 days of training on eight NVIDIA P100 GPUs; the base model trained in about 12 hours. Beating the previous best and doing it at a fraction of the compute was the combination that made the wider field sit up: this was not a marginal tweak, it was a better way to build.
5. One architecture, a whole era
The deepest surprise came later: the Transformer was not really a translation model at all. It was a general-purpose engine for sequences of anything. Feed it text, pixels, audio, or amino acids, and the same core machinery learns the patterns. Within a few years it had swallowed most of AI.
| Built on the Transformer | What it does |
|---|---|
| BERT (2018) | Encoder-only model that reshaped search and language understanding |
| GPT series → ChatGPT | Decoder-only models behind the chatbot boom (the T is Transformer) |
| Claude, Gemini, Llama | Today’s frontier large language models |
| Vision Transformer (ViT) | Brought the same idea to image recognition |
| DALL·E, Stable Diffusion, Sora | Image and video generation |
| AlphaFold | Attention-based modeling that helped crack protein structure |
As of 2026, Attention Is All You Need has been cited more than 250,000 times, placing it among the ten most-cited scientific papers of the century — a rare distinction for a work barely a decade old.
6. Eight authors, one Beatles reference, and a diaspora
The paper carries a human story as memorable as its math. The eight authors insisted on being credited as equal contributors, with the author order literally randomized. The name of the network came from Jakob Uszkoreit, who simply liked the sound of the word “Transformer,” while the paper’s playful title was a nod to the Beatles’ “All You Need Is Love.”
What happened next may be the ultimate measure of the work’s influence: all eight authors eventually left Google, and went on to found or lead a remarkable share of the modern AI industry.
| Author | Where they went |
|---|---|
| Aidan Gomez | Co-founder & CEO, Cohere |
| Noam Shazeer | Co-founded Character.AI; later returned to Google to help lead Gemini |
| Ashish Vaswani & Niki Parmar | Co-founders, Essential AI (earlier, Adept) |
| Llion Jones | Co-founder & CTO, Sakana AI (Tokyo) |
| Jakob Uszkoreit | Co-founder & CEO, Inceptive (AI-designed RNA medicines) |
| Illia Polosukhin | Co-founder, NEAR Protocol |
| Łukasz Kaiser | Researcher, OpenAI |
Why it still matters
Nearly every headline about AI today — a new model, a new capability, a new record — traces back through a lineage that begins with this one paper. Its genius was not a single trick but a reframing: that a model does not need to march through data in order if it can instead learn, all at once, what to pay attention to. That simple shift unlocked scale, and scale unlocked everything that followed.
Some papers describe the world. A rare few build the one we live in. Attention Is All You Need is one of them.
Sources & further reading
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, ‘Attention Is All You Need’, arXiv:1706.03762 (2017); presented at NeurIPS 2017
- Wikipedia: Attention Is All You Need · Transformer (deep learning architecture)
- Image: Transformer architecture diagram by dvgodoy (Daniel Voigt Godoy), via Wikimedia Commons, licensed CC BY 4.0
Curated by Jerry Cards - jerrycards.com. Our 致敬 (tribute) series celebrates the landmark papers and discoveries that quietly built the modern world. More at jerrycards.com/news.